How I Used LLMs to Run a Benchmark and Write a Paper
A practical walkthrough of how I used LLMs to design, evolve, benchmark, and write up a real experiment on agent-doc architecture.
I wanted to answer one practical question:
Can documentation architecture change coding-agent quality on hard tasks, or does it mostly change cost?
But I also wanted to run the process in a way other people can copy. So instead of treating an LLM like a one-shot writer, I used it as a research copilot across the full loop:
- define a testable question
- generate and harden tasks
- run controlled benchmarks
- review failures
- iterate the experiment
- publish a paper from artifacts
This post is that workflow.
The setup I tested
Three architectures, same policy facts:
control: no policy docsmono: one long root policy doctoc: index + modular docs
Two models:
- Claude Code (
claude-sonnet-4-5-20250929) - Codex (
gpt-5.3-codex)
Final run size:
42attempts per model14attempts per architecture- per-attempt isolation with deterministic grading
How the experiment evolved (the part that mattered)
The important part was not the first run. It was the iteration.
Phase 1: benchmark looked “fine” but was too easy
Early versions gave high scores for both mono and toc.
That looked good, but it was not useful because there was no separation signal.
Phase 2: we reviewed failures and tightened tests
I used LLMs to inspect graded artifacts and find what was actually failing:
- not basic execution
- mostly policy-binding details (error shape, call order, folder-specific conventions)
So I made the scenario harder (repo_policy_conflict_v3):
- more multi-file, multi-phase tasks
- more conflicting distractor policy under
highload - stricter checks on validation order, wrapping, and exception rules
This changed the benchmark from:
- “can the model write Go code?”
into:
- “can the model retrieve and correctly apply policy under interference?”
Phase 3: rerun clean, balanced, and isolated
Then I reran with balanced sampling and strict isolation, and only used that run for headline claims.
That was the first version that produced a robust quality ranking.
Final result (v3 full42 clean)
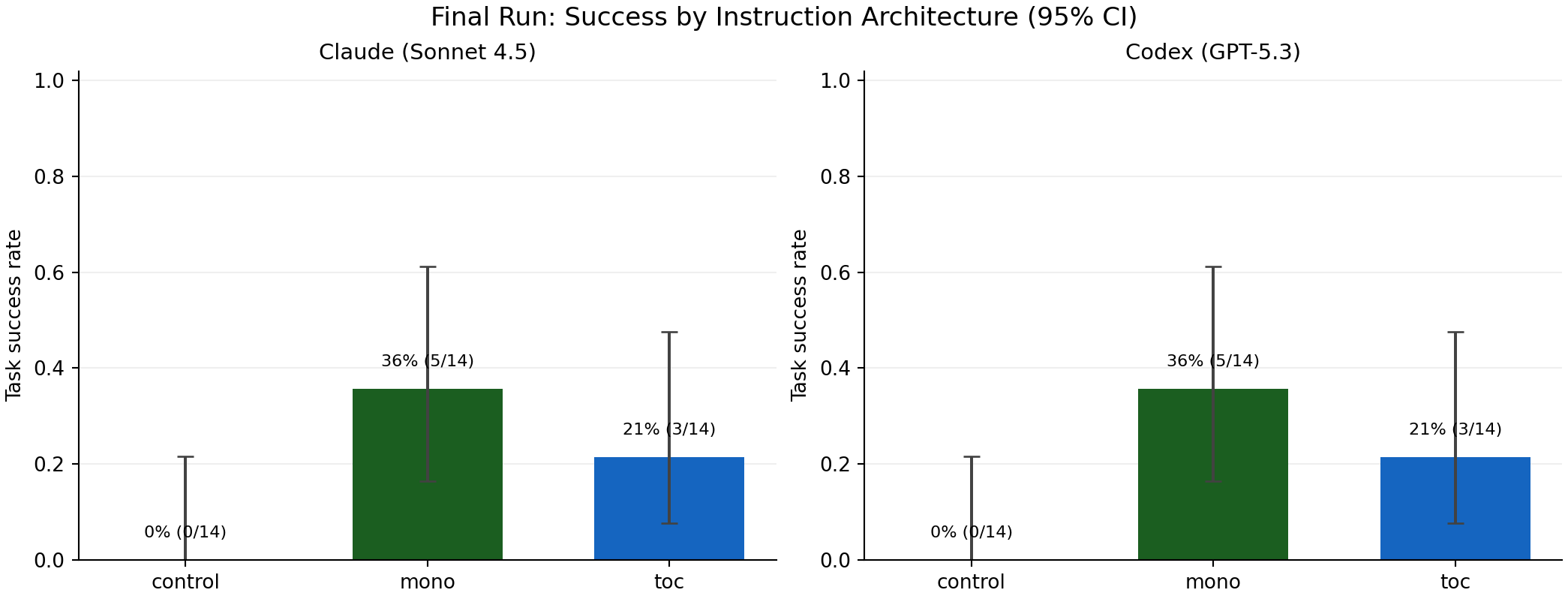
mono outperformed toc, and both beat control.Per model, same ranking:
control:0/14(0.0%)mono:5/14(35.7%)toc:3/14(21.4%)
A key detail: functional_pass stayed at 100%.
So misses were mostly policy-adherence misses, not coding-execution misses.
Cost and retrieval behavior
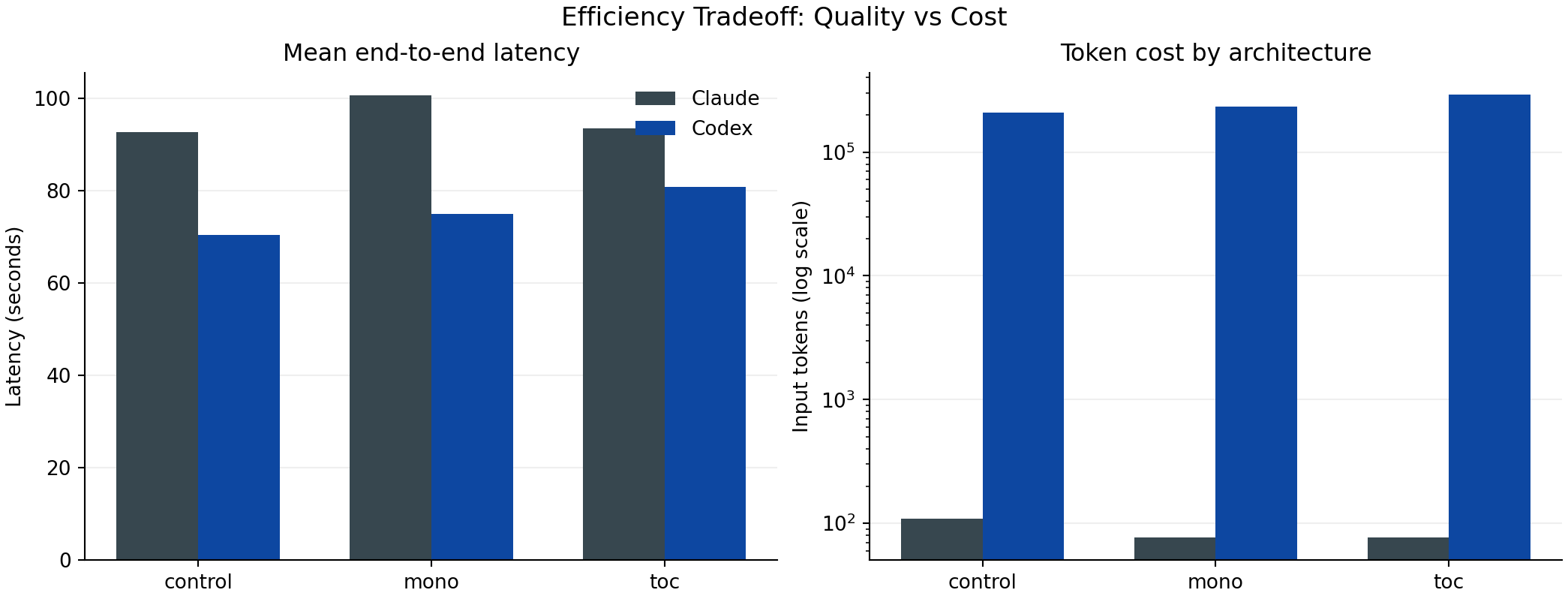
toc increased retrieval and cost, especially for Codex.Codex in this run:
tocinput tokens vsmono:+24.8%toclatency vsmono:+5.9s
Docs read means:
- Claude:
mono 1.00vstoc 4.50 - Codex:
mono 1.36vstoc 5.86
So more document retrieval did not automatically produce better policy success in this task set.
Task-level discrimination (why this benchmark is useful)
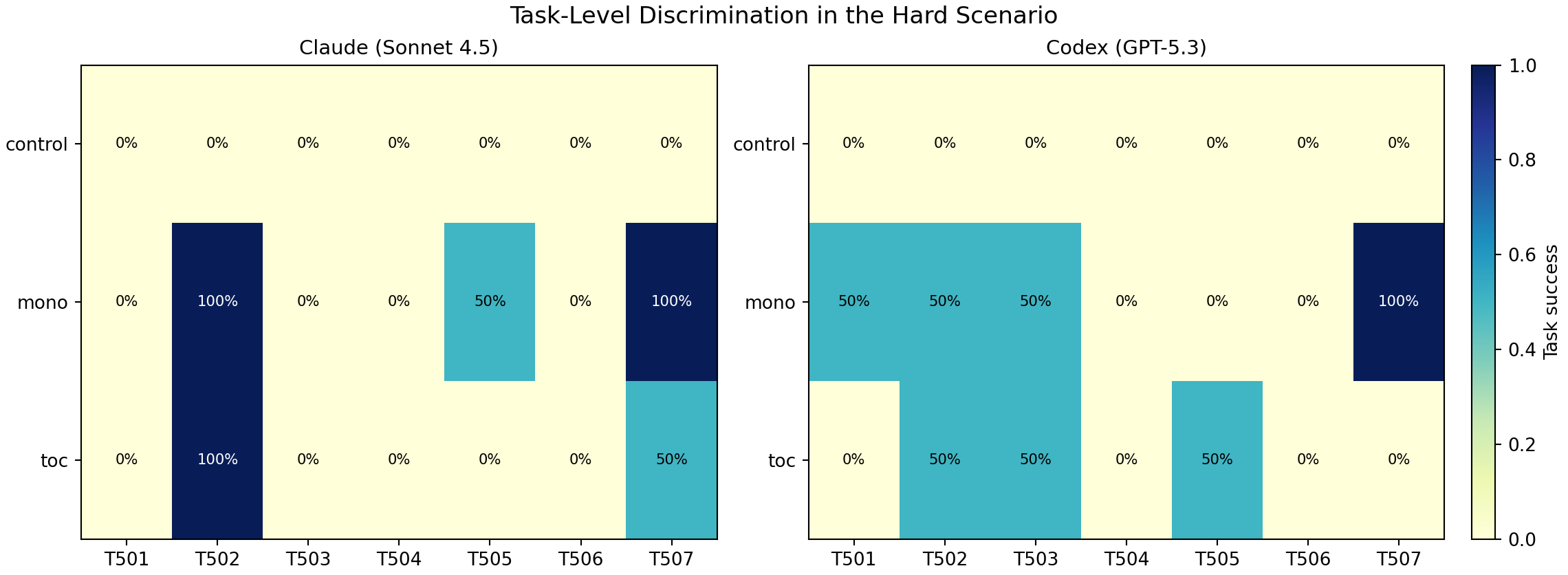
Hardest classes:
T504 legacy_timezone_boundary: 0%T506 round_touched_file_migration: 0%T501 currency_alias_normalization: low success
Highest-signal split:
T507 cross_folder_multi_phase:mono 100%vstoc 25%(pooled)
This is exactly the kind of separation I could not get in earlier saturated runs.
What I learned about using LLMs for research
Using an LLM for research worked best when I split responsibilities:
- LLM for generation: draft tasks, checks, protocol language, paper structure
- Code/tests for truth: execution + grading scripts decide outcomes
- LLM for iteration: summarize misses, suggest next trial changes
- Artifacts for writing: all paper tables/figures generated from saved results
The failure mode is obvious in hindsight: if you only ask an LLM to “write a paper,” it can sound convincing without being grounded. The fix is simple: force everything through runnable checks and machine-readable artifacts.
Quick playbook (copy this)
If you want to do your own benchmark and write-up quickly:
- Start with one causal question.
- Build a runnable fixture repo with realistic conflicts.
- Encode policy facts and distractors in structured files.
- Generate variant architectures automatically.
- Run isolated attempts with balanced sampling.
- Grade function and policy separately.
- Review misses and harden tasks.
- Only then publish, using generated tables/figures.
That is the shortest path I know from “idea” to “credible research-style result” using LLMs.
Trial progression (why iteration mattered)
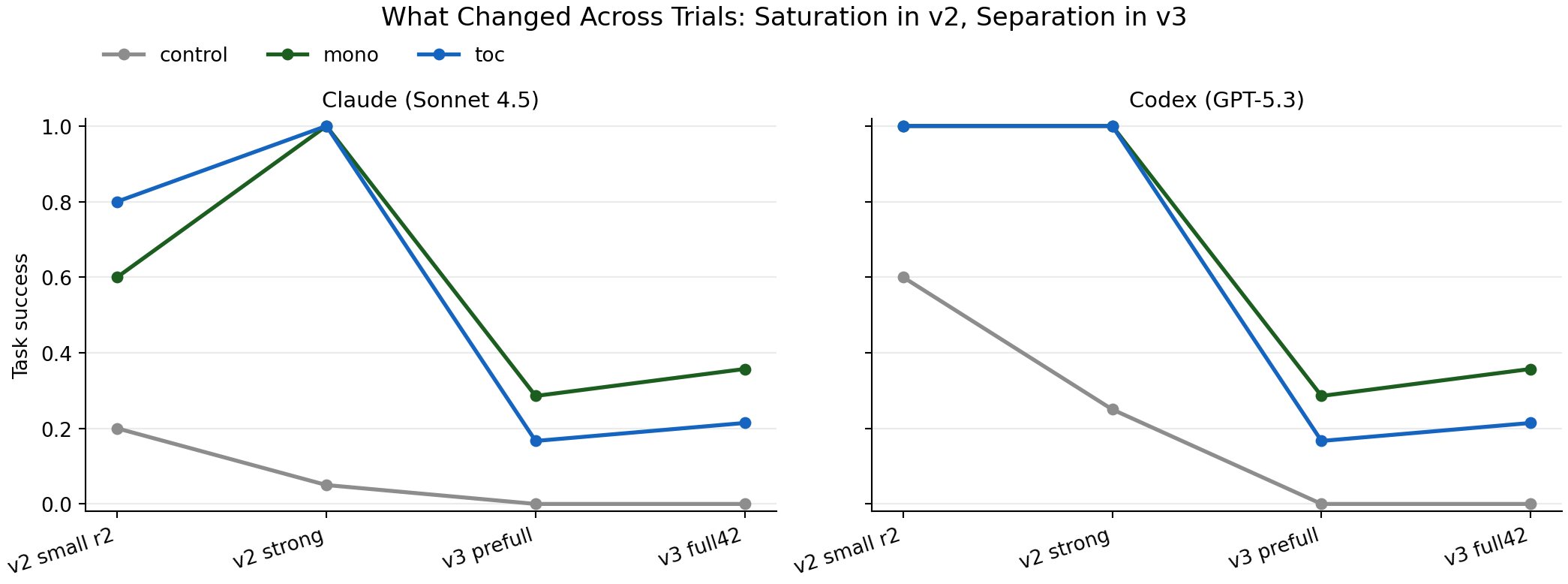
The stack looked like this:
v2_small_r2_regrade: early signal, unstablev2_strong_r1: quality saturation (mono/tocboth near ceiling)v3_smoke: wiring checkv3_prefull18_clean: first consistentmono > tocdirectionv3_full42_clean: larger balanced confirmation
The practical lesson: benchmark hardness usually matters more than sample size when your benchmark is saturating.
Reproducibility
Primary artifacts:
benchmark-memory/results/raw_results_claude_repo_policy_v3_full42_clean.jsonlbenchmark-memory/results/raw_results_codex_repo_policy_v3_full42_clean.jsonlbenchmark-memory/results/graded_results_claude_repo_policy_v3_full42_clean.jsonlbenchmark-memory/results/graded_results_codex_repo_policy_v3_full42_clean.jsonlbenchmark-memory/results/summary_claude_repo_policy_v3_full42_clean/summary_by_architecture.csvbenchmark-memory/results/summary_codex_repo_policy_v3_full42_clean/summary_by_architecture.csvbenchmark-memory/results/summary_claude_repo_policy_v3_full42_clean/summary_by_task.csvbenchmark-memory/results/summary_codex_repo_policy_v3_full42_clean/summary_by_task.csv
Figure generation:
cd benchmark-memory
python3 scripts/plot_repo_policy_v3_full42_results.py
Sources
- Claude Code memory docs: https://code.claude.com/docs/en/memory
- Anthropic context windows: https://docs.anthropic.com/en/docs/build-with-claude/context-windows
- Codex prompting guide: https://developers.openai.com/codex/prompting/
- Codex
AGENTS.mdguide: https://developers.openai.com/codex/guides/agents-md