What We Actually Learned About Agent Docs: Mono vs TOC, Claude Code vs Codex
I got tired of hearing a familiar sentence: “the model forgot.”
Sometimes that is true. Sometimes the benchmark is bad.
So I rebuilt the experiment from scratch to answer one concrete repo question:
If you care about policy recall in real code tasks, is a long single
AGENTS.md/CLAUDE.mdworse than a TOC + modular docs architecture?
This post replaces my earlier draft with the stronger run.
Hook: the practical pain
In production repos, we add instructions like:
- use
testify/require - migrate touched assertions
- this folder is an exception
Then the agent edits tests in a different folder and drifts toward old local style.
That drift is exactly what this benchmark tries to measure.
Background context
Claude Code memory and instruction handling
Claude Code has layered memory and instructions:
- project instructions (for example
CLAUDE.md,.claude/rules/*) - optional user/project memory stores
- runtime context and compaction behavior as conversations grow
This means instruction-following depends on what is active and retrieved at task time, not just what exists somewhere in the repo.
Codex memory and instruction handling
Codex follows instruction discovery through AGENTS.md rules and directory scoping, then uses thread context for tool calls, file reads, and edits.
In practice, this has two implications for benchmarking:
- instruction architecture can change what gets read early
- context growth and tool behavior can dominate outcomes if isolation is weak
So the experiment must control for both document content and execution isolation.
Hypothesis
I tested three hypotheses:
- Any explicit docs architecture (
monoortoc) beats control on policy recall. tocandmonomay tie on recall, but differ in cost (latency/tokens).- If failures happen, they should concentrate on policy-sensitive tasks, not basic functional correctness.
Experiment design
Scenario
I used the repo_policy_conflict benchmark scenario in benchmark-memory with realistic code-edit tasks in a Go fixture repo.
Task families:
T401: new tests should userequire/error assertionsT402: legacy folder exception (no testify)T403: touched-file migration torequireT404: adapter folder exception (package http_test+require)T405: multi-phase change with conflicting defaults/exceptions
Architectures compared
control: no policy docsmono: one root doc (CLAUDE.mdorAGENTS.md)toc: index file + modular docs (same facts split by topic)
Core fairness rule: mono and toc had equivalent core facts; only structure changed.
Models and sample size
- Claude:
claude-sonnet-4-5-20250929 - Codex:
gpt-5.3-codex - Strong run size: 120 attempts total
- 60/model
- 20 attempts per architecture per model (
5 tasks x 4 repeats)
Scoring and isolation updates (critical)
I fixed several flaws from earlier runs:
- added semantic checks (reduced brittle regex-only grading)
- repaired task patterns that over-penalized equivalent code forms
- enforced per-attempt isolated workdirs
- verified no outside-root reads in this final run
Observed run health:
- Claude raw: 60/60
ok - Codex raw: 60/60
ok - outside-root reads: 0 in both models
Results
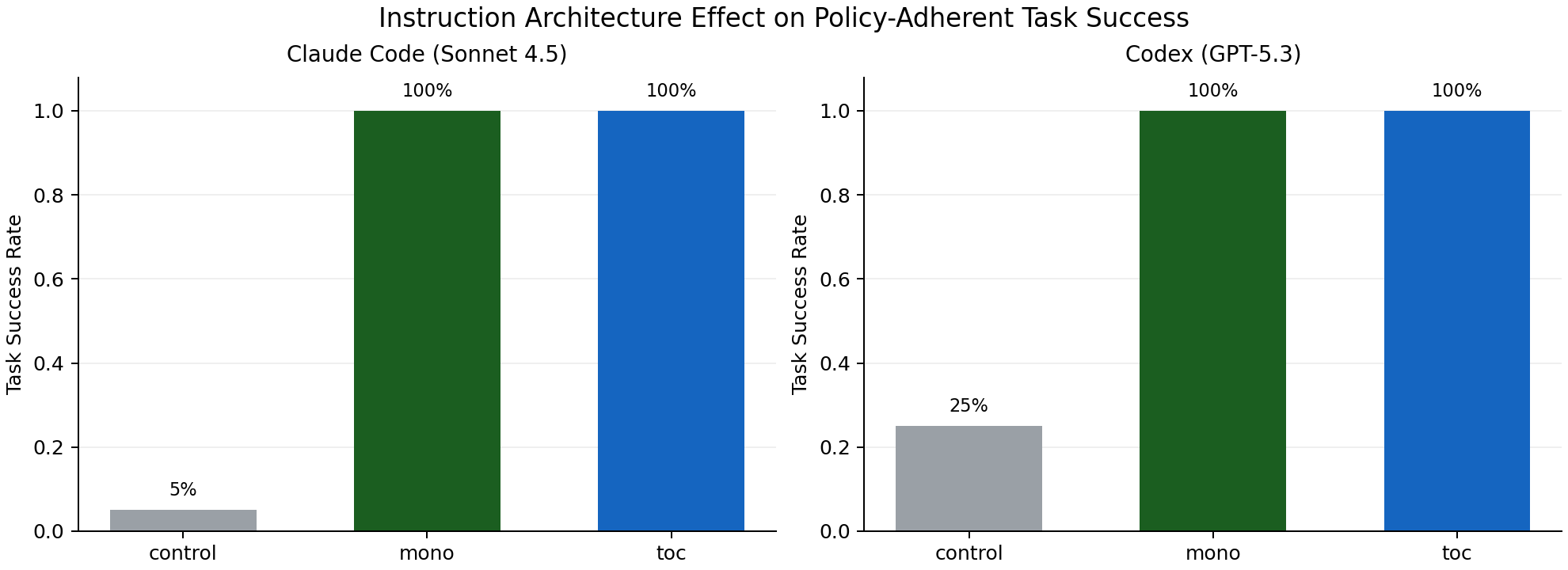
Figure 1: success by architecture
Main result table (strong run)
| Model | Architecture | Task success | Policy pass | Mean latency | Mean input tokens |
|---|---|---|---|---|---|
| Claude | control | 5.0% | 5.0% | 58.2s | 58.4 |
| Claude | mono | 100.0% | 100.0% | 72.7s | 72.8 |
| Claude | toc | 100.0% | 100.0% | 71.2s | 70.0 |
| Codex | control | 25.0% | 25.0% | 69.1s | 206,481.9 |
| Codex | mono | 100.0% | 100.0% | 77.7s | 235,672.7 |
| Codex | toc | 100.0% | 100.0% | 86.8s | 289,331.5 |
Confidence intervals (Wilson, 95%)
| Model | Architecture | Success (k/n) | 95% CI |
|---|---|---|---|
| Claude | control | 1/20 | [0.9%, 23.6%] |
| Claude | mono | 20/20 | [83.9%, 100%] |
| Claude | toc | 20/20 | [83.9%, 100%] |
| Codex | control | 5/20 | [11.2%, 46.9%] |
| Codex | mono | 20/20 | [83.9%, 100%] |
| Codex | toc | 20/20 | [83.9%, 100%] |
Figure 2: efficiency tradeoff
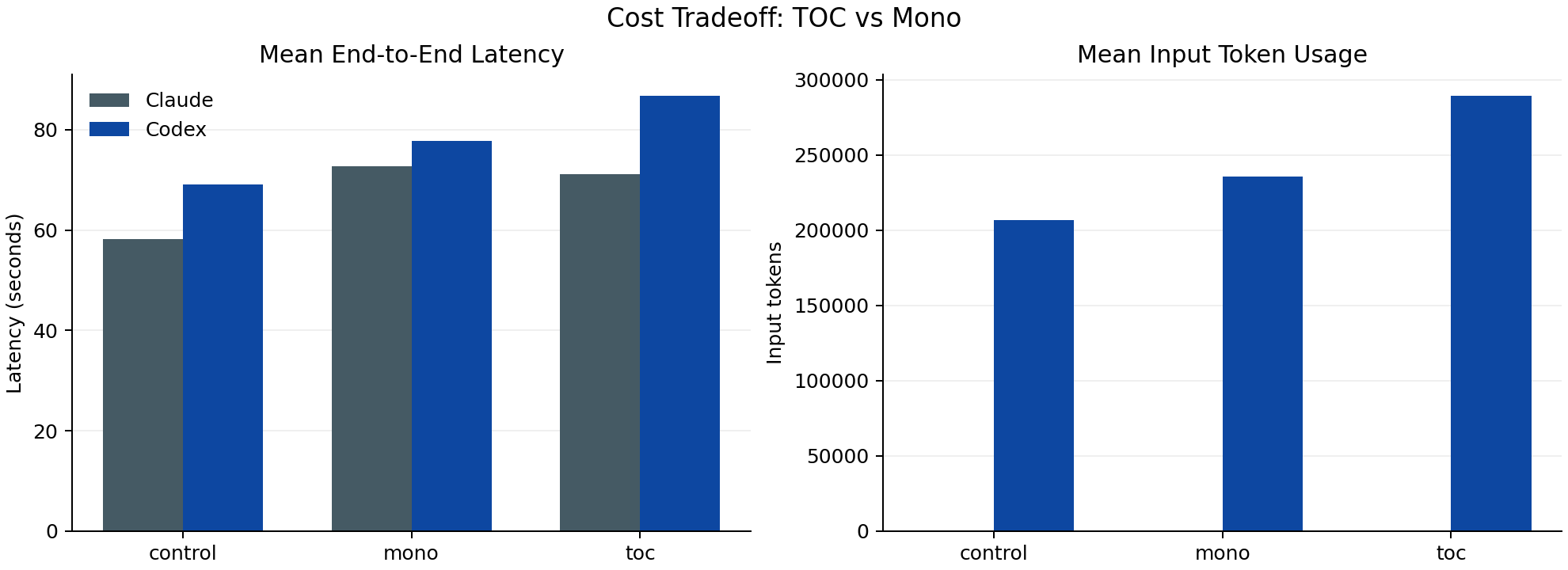
Takeaway: on this task set, mono and toc tie on recall, but toc is costlier for Codex.
Figure 3: task-level heatmap
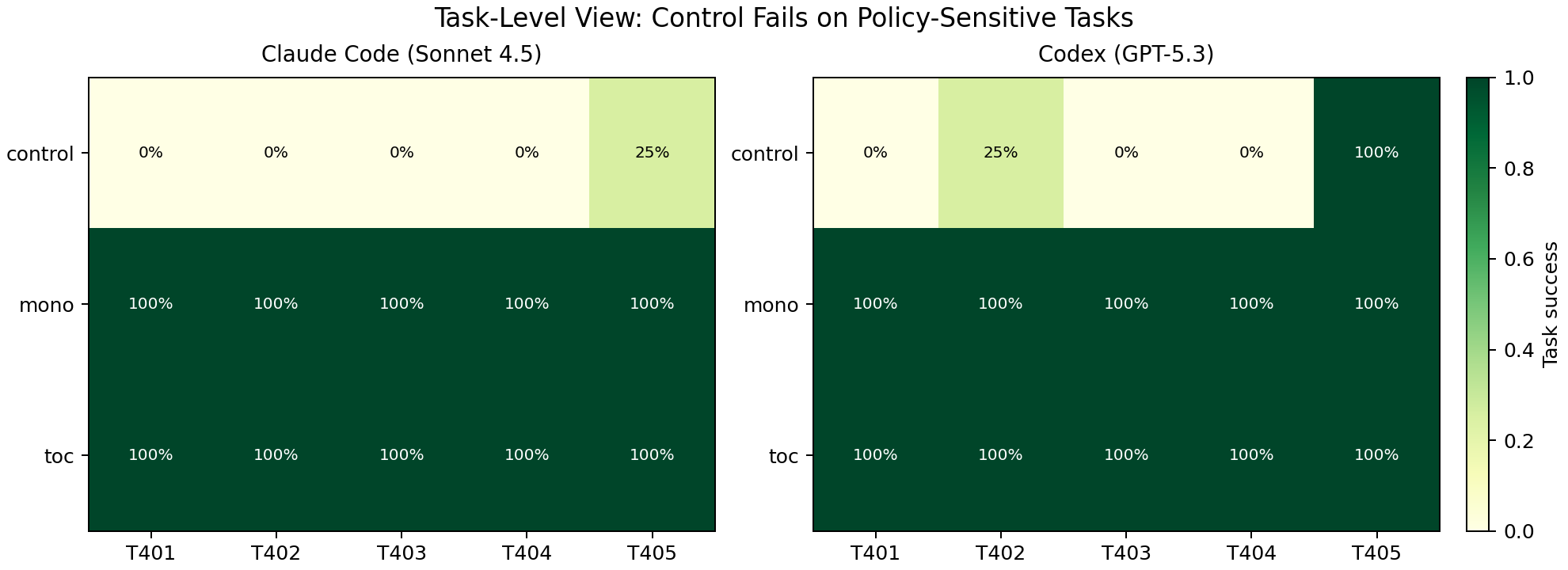
Control failures cluster where policy conflicts are explicit (framework choice, folder exceptions, touched-file migration). Functional checks still passed.
Optional interactive view
For hover details and cross-plot exploration:
Discussion
What this supports strongly
- Documented policy architecture matters.
controlunderperformed sharply in both models. - In this scenario, both
monoandtocare highly effective for recall/adherence. - For Codex,
monoappears more efficient thantocat equal quality.
What this does not prove yet
- That
tocis universally better or worse thanmonofor recall. - That long docs always create harmful noise.
Current interpretation: with a clean policy set and this task complexity, both structured approaches saturate quality. Differences become mostly economic (latency/tokens), especially for Codex.
Remaining validity limits
- still one repo fixture (Go testing policy domain)
- all runs are single-turn tasks, even for the multi-phase prompt
- perfect recall in
mono/tocsuggests we now need harder discrimination tasks, not only larger N
Next steps
- Add longer multi-turn task chains with delayed policy recall.
- Add contradictory local-code priors (legacy style nearby) to increase interference pressure.
- Include mixed-language repos to test portability.
- Add ablations for file naming/discovery (
CLAUDE.md,AGENTS.md, both, nested overrides). - Publish preregistered rubric + holdout tasks before next run.
Reproducibility
Primary artifacts for this post:
benchmark-memory/results/run_plan_claude_repo_policy_v2_strong_r1.jsonlbenchmark-memory/results/run_plan_codex_repo_policy_v2_strong_r1.jsonlbenchmark-memory/results/raw_results_claude_repo_policy_v2_strong_r1.jsonlbenchmark-memory/results/raw_results_codex_repo_policy_v2_strong_r1.jsonlbenchmark-memory/results/graded_results_claude_repo_policy_v2_strong_r1.jsonlbenchmark-memory/results/graded_results_codex_repo_policy_v2_strong_r1.jsonlbenchmark-memory/results/summary_claude_repo_policy_v2_strong_r1/summary_by_architecture.csvbenchmark-memory/results/summary_codex_repo_policy_v2_strong_r1/summary_by_architecture.csvbenchmark-memory/results/summary_claude_repo_policy_v2_strong_r1/summary_by_task.csvbenchmark-memory/results/summary_codex_repo_policy_v2_strong_r1/summary_by_task.csv
Figure generation command:
cd benchmark-memory
python3 scripts/plot_repo_policy_strong_results.py
Sources
- Claude Code memory docs: https://code.claude.com/docs/en/memory
- Anthropic context windows: https://docs.anthropic.com/en/docs/build-with-claude/context-windows
- Codex prompting guide: https://developers.openai.com/codex/prompting/
- Codex
AGENTS.mdguide: https://developers.openai.com/codex/guides/agents-md