data_engineering.htm
Overview of Data Engineering
Data Engineering Teams
The data engineer is a hub between data producers, such as software engineers, data architects, and DevOps or site-reliability engineers (SREs), and data consumers, such as data analysts, data scientists, and ML engineers. In addition, data engineers will interact with those in operational roles, such as DevOps engineers.
ML Engineers vs. Data Engineer
The ML engineer overlaps with DE, but it develops more advanced ML techniques, train models, and designs and maintains infrastructure running ML processes. It emphasizes more MLOps and other mature practices such as DevOps.
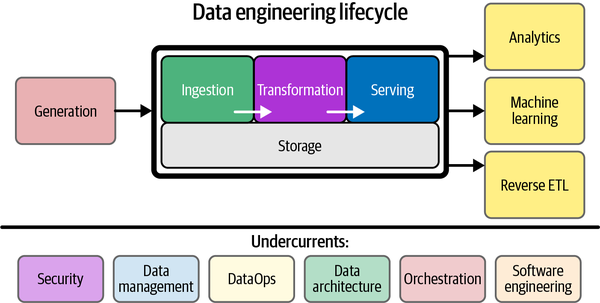
Main components of Data Engineering
Data Generation
- Data is coming from a variety of sources now
- It's hard to keep in the same schema. Schema evolution is now considered part of the Agile approach.
Storage
- Cloud architectures often have several storage solutions
- Hot data is data commonly retrieved many times per day. It should be geared for fast retrieval
- Cold data is seldom queried and mostly for archival purposes.
Ingestion
- A common bottleneck of the lifecycle; source systems are outside of your direct control and might have data of poor quality
- The separation of storage and compute makes streaming more popular
- Can my downstream services handle the volume of data I'm sending them?
- Batch is still widely used because of legacy systems, streaming can be useful but it creates increasing amounts of complexity
Key Questions:
- What are the use cases for the data?
- What is the destination?
- In what volume will it arrive?
- What format is the data in?
Transformation
- Change data into correct types, put records into standard formats, remove bad ones
- Large-scale aggregation for reporting or featurizing data for ML processes
Serving
- Data is served for analytics, ML, and reverse ETL
- Before investing into ML, companies need to build a solid data foundation
- This means setting up the best systems and architecttures across the data engineering and ML lifecycle.
- Analytics then ML
- Reverse ETLs feed bvack the data into source systems. It's useful for businesses relying on SaaS.
Data Ops
- DataOps automation has a similar framework and workflow to DevOps, consisting of change management (environment, code, and data version control), continuous integration/continuous deployment (CI/CD), and configuration as code.
- DatOps consist of automation, observability and monitoring, and incident response
Observability and Monitoring
- Data is a silent killer; bad data can linger in reports for a long time
- You need to implement observing, monitoring, logging, alerting, and tracing
- DODD focused on making data observability a first-class consideration in the data engineering lifecycle
Data Architecture
Types of data architectures
- Data warehouse: structured, includes the compute
- A subject-oriented, integrated, nonvolatile, and time-variant collection of data in support of mgmt decisions
- Separates OLAP from OLTP
- Centralized and organizes data
- e.g., Snowflake, Amazon Redshift
- Data lake: unstructured, data can be in any format
- Common during big data era
- Data can be queried with MapReduce, Spark, Presto, etc...
- Data lakehouse: combines benefits from both, introduced by
Databricks
- Includes control, data management and data structures
- Still houses data in an object storage and supports a variety of query and transformation engines
Modern Data Stack
- Instead of using monolithic toolsets, use cloud-based, plug and play, off-the-shelf components
- Includes data pipelines, storage, monitoring, etc...
Data Generation
Data Logs
- Insert only: always retain the records, add a timestamp
Messages and Streams
- Message queues and streaming platforms are often used interchangeably
- A message is raw data communicated across two or more systems
- A message is normally sent through a message queue from a publisher to a consumer
- Once the message is delivered, it is removed from the queue
- A stream is an append only log of event records
- You use streams when you care about what happened over many events
Types of time
- Event time; event is generated
- Ingestion time; event is ingested
- Process time; event is processed
Ways of ingesting data
- APIs
- REST
- GraphQL
- WebHooks
- Event based data transmission pattern
- Data source can be an application backend, a web page, or a mobile app
- RPC and gRPC: remote procedure call library; bidirectional exchange
of data over HTTP/2
- Imposes more technical standards than REST
- Message queues
- Critical for decoupled microservices and event-driven architectures
- Need to keep in mind the frequency of delivery, message ordering and scalability
- Some issues with queues can be the order of the messages
- Ideally, should be idempotent; outcome is the same after processing it multiple times
- Event streaming platform
- Produces data in an ordered log of records
- Includes
- Topics - collection of related events
- Stream partitions
- Tend to be more fault tolerant because they're distributed
Ingestion undercurrents
- Security: how is the data secured and encrypted; do we have a VPN, or an SSO?
- Data management: who manages the data, what's the quality, what if the schema changes, is the data HIPAA?
- DataOps: how will we know when there's an issue, how are we monitoring, is the schema conformant, what do we do if something bad happens
- Architecture: what if the system fails, what do we do if we lose data, how available are the sources, who's in charge of them
- Orchestration: how often do we recieve the data, can we integrate with the upstream application team
- SWE: Can the code access with the right credentials, how do we authenticate, how do we access (API, REST), can we parallelize the work, how do we deploy code changes?
Storage
The raw ingredients are: disk drives, memory, networking and CUPU, serialization, compression and caching
Raw Ingredients
- Magnetic Disk Drives
- They can be slow but are cheap
- They are constrained by disk transfer speed and rotational latency
- Storing info in parallel can make them faster
- The max speed is 200-300 MB/s (20 hours for 30 TB)
- Used widely because of how cheap they are
- If we use multiple, the bottleneck becomes network and CPU
- Solid State Drives
- Stores data in flash memory cells
- They're really fast (0.1 ms)
- Used for OLTP Systems; allow Postgres
- Cost 20-30 cents per GB (10x magnetic drives)
- SSD can be used in some OLAP for caching
- RAM
- Attached to CPU; stores code
- It's volatile, if it fails it gets reset
- 1000 times faster than SSD
- $10/GB
- Stores data in capacitors, needs to be refreshed over time
- Networking and CPU
- Availability zones impact the storage access
- Trade off in spreading data vs. keeping it under on zone
- Serialization
- Flattening and packing data into standard format that reader will be able to decode
- e.g., Apache Parquet
- Compression
- Increasing scan speed per disk
- Caching

Data Storage Systems
BASIC
- Basis of eventual consistency
- Basically available; consistency is not guaranteed
- Soft state - state of transaction is fuzzy
- Eventual consistency - at some point, reading data will return consistent values
Why do BASIC? It allows us to use large-scale distributed systems. i.e., scale horizontally.
When do we do strong consistency? When we can tolerate longer query times but want the correct data every time.
Types of file storage
- Cloud filesystem services: e.g., Amazon Elastic File System; exposed through the NFS4 protocol
- Block storage: type of raw storage provided by SSDs and magnetic disks; standard for VMs
- RAID: redundant array of independent disks. Controls multiple disks to improve data durability, enhance performance, and combine capacity
- Cloud virtualized block storage: similar to storage area network (block storage over a network). They separate data from the host server. Can persist the data when an EC2 instance shuts down. Highly scalable.
- Object storage - contains objects of all shapes and sizes. Amazon
S3, Azure Blob Storage. We lose a lot of the writing flexibility with
file storage on a local disk. Objects are written once as a stream of
bytes. To change data or append you must rewrite the full object.
- Object stores are the gold standard for data lakes.
- Object stores are key value stores.
- We have bucket names and item values
- Cache and Memory Storage systems: e.g., memcached, a key-value store desgined for caching db query results, api call repsonses and more. Redis, a key-value store, supports more complex data types. Can tolerate a small amount of data loss.
- Streaming storage: stored data is temporal. Kafka now allows long data retention.
Data abstractions
- Data warehouse: standard olap architecture.
- Data lake: massive store where data was retained raw and unprocessed. Originally built on Hadoop systems. Now we're separating compute and storage.
- Data lakehouse: combines aspects of the data warehouse and data lake. Stores data in object storage. Adds robust table and schema support for incremental updates and deletes. Has file management layer with data mgmt and transf tools. Easier to send data when other tools can directly read from the object
Data Ingestion
It's the process of moving data from one place to the other. A data pipeline is the combination of architecture, systems, and processed that move data through the stages of the DE lifecycle.
Considerations:
- Bounded vs. unbounded
- Discrete batches or stream of consciousness (stream of data)
- Frequency
- Batch, micro batch or real time (or streaming)
- Sync or async
- With sync, the source, ingestion, and destination have complex dependencies and are tightly coupled
- With async, dependencies can operate at the level of individual events; like microservices.
- Serialization or deserialization
- Encoding the data from the source and preparing data structures for transmission
- Throughput and scalability
- Will your ingestion be able to keep up with a sudden influx of backlogged data
- Reliability and durability
- Reliability entails high uptime and proper failover for ingestion systems
- Durability entails making sure data isn't lost or corrupted
- Need to build redundancy and self healing based on the impact and cost of losing data
- Payload
- Data type
- Data shape (json, tabular, unstructured)
- Schema
- Push vs. pull vs. poll patterns
- If there's a change, pull (polling)
- Push from source to destination
- Destination pulls from source
Ways to ingest data
- Direct DB connection
- OBDC or JBDC via API
- Change Data Capture
- Ingesting changes from a source system
- Batch oriented CDC; every 24 hours update changes in records
- Continuous CDC; capture all table history and support near real time data ingestion
- CDC can consume database resoures, CPU time, network bandwitdth, disk bandwidth
- APIs
- Increasingly popular
- Common with SaaS platforms
- Message Queues and Event-Streaming
- Managed data connectors
- Managed by vendor
- SFTP and SCP; run over SSH connection
- Webhooks; aka reverse APIs
- The data provider defines an API request spec; iit makes the API calls rather than receiving them
- The consumer needs to provide an endpoint for the provider to call
- Can be brittle, difficult to maintain and inefficient
- Web scraping
Undercurrent of data ingestion
- DataOps
- Need to monitor uptime, latency, and data volumes
- How will you respond if ingestion job fails
- Monitoring should be there from the beginning
- Is there proper testing and deployment automation? Can you roll it back?
- Data quality
- Data can regress whenever and without warning
- Need to monitor statistics, spikes, etc...
- Implement logs to capture history, checks, exception handling
- Can you do some statistical data testing? averages, nulls, outliers?
Data Transformation
The lifetime of a SQL query is:
- Query issued
- Parsing and conversion to bytecode
- Query planning and optimization
- Query execution
- Return results
A data model represents the way data relates to the real world. How it must be organized to reflect the organization's processes, definitions, workflow and logic.
Types of normalization (Codd normal forms)
- Denormalized - no normalization, nested and redundant data allowed
- First normal form - each column is unique and has a single value; table has a unitque primary key
- Second normal form - 1NF plus partial dependencies are removed
- Third normal form - 2NF plus each table contains only relevant fields related to its primary key and has no dependencies
Data modeling
- Star schema: data is modeled with two general types of tables: facts
and dimentions
- Facts is a table of numbers. e.g., order ID, customer key, date key, gross sale amount
- Dimension tables as qualitative data referencing a fact; smaller than fact tables. e.g., datekey, year, quarter, month, day of week.
Update patterns
- Truncate and reload; wipe old data and reload
- Insert only; insert new records without changing or deleting old records.
- Delete; deletes are more expensive than inserts in columnar system. Insert deletion inserts a new record with a deleted flag. Queries can get more complicated
- Upsert/merge; upserting takes a set of source records and looks for matches using a primary key. When it matches, it updates the record, otherwise it inserts the new record.
Serving data
What a data engineer should know about ML:
- When to use which models?
- How to wrangle data for unstructured and structured data?
- How to encode data for various types
- Batch vs. online learning?
- When to use AutoML vs. handcrafting an ML model?
- Classification vs. regression
- When to train locally, on a cluster, or at the edge
- What are data cascades?
New trends in data engineering
- Application stacks will be data stacks. Applications will integrate real time automation and decision making powered by streaming pipelines and ML
- We will have a live data stack; application and source systems will feed data to low latency fast query processing DBs, which will feed data to report, analytics, and ML
- We will have more streaming pipelines and real time analytical DBs
- Data will move in a contiguous flow moving away from batch ingestion
- Shift away from ELT and more to stream transform and load.
- This live data stack will be powered by OLAP DBs built for streaming
- We will have tighter feedback loops between applications and ML.